

You can watch a video to learn more about using special days to improve forecasting accuracy.
When you're reviewing the Forecast Data step, you see both the forecasted volume and AHT for all selected skills. The data might seem inaccurate, while you're expecting to see normal values:
-
You see in some areas where the AHT or volume is unusually low or at 0.00.
-
You see volume peaks on Tuesday and Wednesday, but the Historical data shows peaks on Monday and declining trends till Friday.
In these cases, consider making changes to the historical data.
In the Historical Data step, look for days that don't quite follow the standard. For example, the volumes might be too high for a certain day due to a product promotion. This isn't a standard day. Because of this, the forecasting data will show an inaccurate volume or AHT for some skills.
To improve the accuracy of the forecasted volumes and AHT, define those days as Special Days. In the special day settings, choose to Exclude this day from future forecasts. Those days won't be taken into consideration within the Forecasting Data step.
When the forecasted interaction volume for a whole day is 0, you won't be able to edit the volume.
You can check that the volume for the entire day is 0 by viewing the data by day (1D). In the day view, you see data for each interval during the day.
If the volume for all intervals is 0, this is why you cannot edit the data.
To be able to edit the volume, change at least one interval.
For example, the forecasted interaction volume is 0 on January 25th. You are currently looking at the month view (1M). In this case, you won't be able to edit or bulk edit.
To edit the volume for the 25th:
-
Go to day view (1D).
-
Edit a least one interval. Let's say, Jan 25 8:00 AM. Instead of 0, write 1 or the desired value for that interval.
-
To make changes for the whole day, go back to month view (1M) and edit.
When you create a forecasting job, the system calculates the forecast data in two stages. First, the data is generated in Forecast Data (step 3 of forecasting), based on the required skills. Second, the system can improve the forecast data by distributing the workload across multiple scheduling units. After defining the Staffing Parameters (step 4), the data is regenerated. This time, the calculation also considers the scheduling units that can handle the interactions. This ensures that the forecast data is as accurate as possible. The forecast data is updated in Staffing (step 5).
When you generate a schedule based on a forecasting job, the forecast data is based on the data in step 5. The final forecast data is also displayed in the Forecast columns in Intraday Manager.
During the forecast process, (step 3) involves generating a raw forecast, focusing solely on volume and Average Handling Time (AHT) per skill, without considering the agents. From (step 3) to (step 5), a simulation process occurs, distributing agent requirements to each scheduling unit that handles the forecasted skills. These requirements are then translated back into volume per skill per scheduling unit.
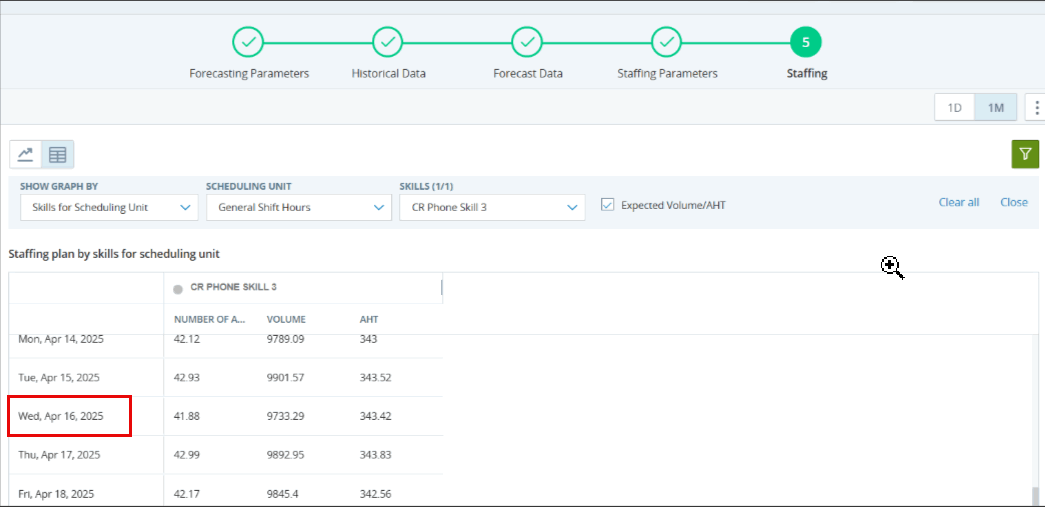
In (step 5), as shown in the screenshot, we can observe the volume and AHT for the interval from 8:00 AM to 8:15 AM, indicating the expected number of contacts to be handled per scheduling unit per skill as a result of the simulation.
Let's say you activated ACD on April 2021. This is when historical data starts to get collected. Then, you activated WFM on November 2022. Because you have been collecting historical data for over a year, you should be able to use it automatically when generating a forecast.
However, the forecast job says that there's no historical data (in step 2). To solve this, you need to contact support. They will import the historical data that you collected into WFM.
The system is working as it was designed to. The auto-select feature automatically chooses the best forecasting model based on past data. In this case, the system chose the model that seemed most accurate for the data it was given. Even though it produced a spike on Thursdays, this is part of the system’s intended function — it selected what appeared to be the best option based on past results.
The difference in results comes from how the two models handle the data:
-
The auto-select model picked a forecasting method that worked best for the past data, but it picked up on a weekly pattern (like the Thursday spike) and carried it into the future.
-
The Exponential Smoothing (ES) model smooths out data, which made it less sensitive to those Thursday spikes and produced a more stable forecast.
Both models are giving different results because they are designed to handle the data in different ways, and each model has its strengths depending on the data’s behavior.
The auto-select model is doing exactly what it was designed to do it chooses the model that it determines will give the most accurate forecast based on historical data. However, in rare cases like this one, the model might pick up on unusual patterns that don’t hold true for the future, such as the Thursday spike. The customer can use the auto-select feature, but in some specific situations, they may need to manually choose a different model (like Exponential Smoothing) to get a more accurate forecast.
Considering the customer is an advanced license holder, they have the option to manually select the forecast model whenever they feel that the auto-selected model is not providing the best results. This flexibility allows them to choose the most suitable model for their specific needs.
In the staffing screen for the below job, let us consider one interval on January 15th for the skill "Contact Center," as highlighted in the image below:
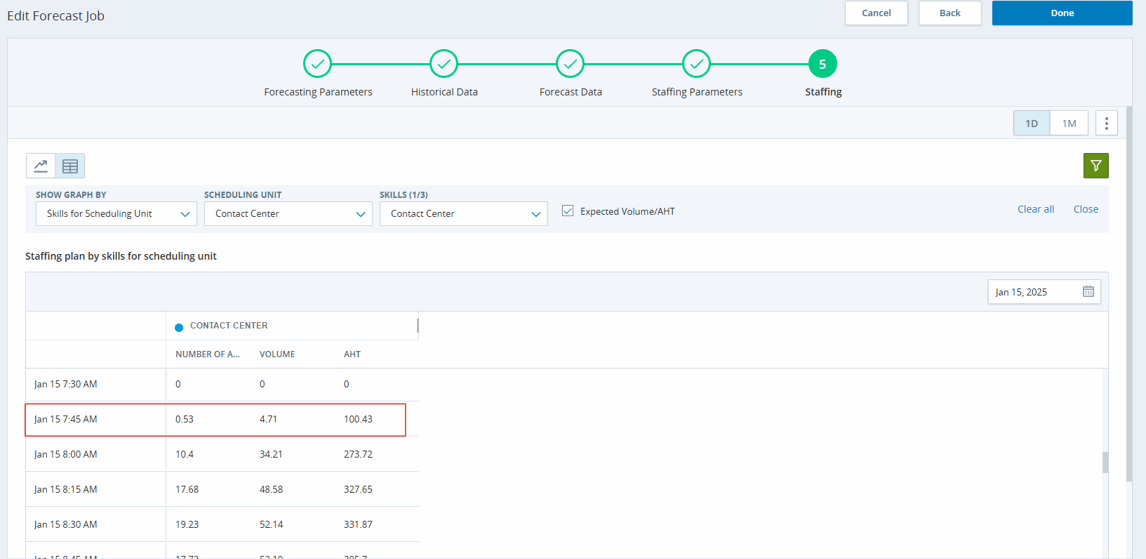
In the example above, we can see that the volume is 4.71 with an AHT of 100.43 for the skill Contact Center. This means that within a 900-second (15-minute) interval, all calls will be handled by a single agent with an AHT of 100.43. If we use the exact figures in our calculations, the staffing requirement of 0.53 is correct, as there are 67 agents in the scheduling unit.
Changing the service level does not impact staffing because we have enough agents to handle the calls. When we look at the Contact Center configuration in the scheduling unit during staffing generation, we see that there are a total of 67 agents available to handle calls for the selected skill. Therefore, when staffing requirements are generated, if there are enough agents available to handle the forecasted interactions in each interval, SLA ASA is not considered.
However, if insufficient agents are available to manage the forecasted calls during a given interval, the SLA ASA metric is utilized to determine the number of agents required to meet service level targets. This principle applies to all intervals, skills, and scheduling units for this role. Considering the low volume and AHT, and the adequate number of agents available, the staffing numbers remain unchanged, since there are enough agents to consistently meet the 100% SLA, the ASA is effectively calculated as zero.
Based on the historical data request, we verify whether the ACD skill is inbound or outbound and whether the WEM skill direction is inbound or outbound. If they do not match, a message on the historical page indicates a mismatch in direction.
Error message:
-
WEM Skills direction not matching with ACD. Align these WEM skills with ACD: Customer Support OB.
Possible Causes:
-
Case 1: The WEM skill is inbound, but the ACD skill mapped to it is outbound.
-
Case 2: Both the WEM and ACD skills are outbound, but the historical data uploaded is marked as inbound.
-
Case 3: Both the WEM and ACD skills are inbound, but the historical data uploaded is marked as outbound due to the outbound flag being set to True during the upload.
-
Case 4: The ACD skill was deleted and recreated. In this case, the original mapping between the WEM skill and the ACD skill is lost.
Workaround:
-
Ensure that historical data is uploaded in alignment with the ACD skill configuration. If the ACD skill is defined as outbound, set the isOutboundFlag to True during the upload. Else, if the ACD skill is defined as inbound, set the isOutboundFlag to False.
-
If an ACD skill was deleted and recreated, remap the WEM skill to the newly created ACD skill.
-
In cases where an ACD skill is mapped as inbound, but the associated WEM skill has the Assign to Channel set to Dialer, the WEM skill must be deleted. Create a new WEM skill of type inbound and associate it with the appropriate inbound ACD skill.
-
Reload historical data from WFM > Forecasting > ACD Historical Data and ensure that at least 13 weeks of historical data are available for accurate forecasting.
In NiCE CXone WFM, Target ASA (Average Speed of Answer) is an optional parameter used in staffing calculations.
-
You can define a Target ASA as part of your staffing parameters, but it is not mandatory.
-
If you do not define a Target ASA, the staffing process will still run using other inputs, such as the Service Level target, to generate staffing recommendations.
When staffing is generated, the system runs a simulation that models how contacts arrive, queue, and are answered in a real-world ACD. Based on this simulation, the system determines:
-
The number of agents required to meet the defined targets (Service Level and/or ASA).
-
The average actual wait time customers would experience with the calculated staffing.
This actual wait time becomes the Forecasted ASA displayed in Intraday.
-
If a Target ASA is defined, the Forecasted ASA reflects the simulation outcome based on that goal.
-
If no Target ASA is defined, the Forecasted ASA is still calculated automatically as part of the Service Level–based simulation.
Regardless of whether a Target ASA is configured, Intraday always displays a Forecasted ASA based on the staffing simulation.
When multiple service targets such as Service Level, Target ASA, and Maximum Occupancy are defined for the same WEM Skill, NiCE CXone WFM evaluates all targets concurrently during the staffing simulation.
-
The system calculates the number of agents required to meet each individual target.
-
It then selects the highest staffing requirement among them.
For example:
-
Service Level target requires 20 agents
-
Target ASA requires 22 agents
-
Maximum Occupancy requires 18 agents
-
Final staffing requirement = 22 agents (the maximum of the three)
-
This approach ensures that staffing recommendations meet all defined service targets, not just one.
When multiple service targets are defined for the same WEM Skill, the system always staffs to the most restrictive (largest) requirement to ensure all targets are satisfied.
Defining multiple service targets for the same WEM Skill is generally not recommended. Each target drives staffing differently and may introduce conflicting constraints. For example,
-
Service Level and Target ASA aim to reduce customer wait times.
-
Maximum Occupancy limits agent utilization, which may conflict with the goals of SL and ASA.
Despite this, NiCE CXone WFM provides the flexibility to support such scenarios when needed. The Staffing Requirement Calculator evaluates multiple selected targets, whether defined in the Staffing Profile or directly in the Forecast Job, and generates staffing recommendations that satisfy them concurrently.
It is the user’s responsibility to ensure that selected targets are aligned and do not conflict. Activating multiple targets increases the restrictiveness of the staffing solution, which may result in overstaffing or infeasible schedules.
The forecast algorithm uses different methods to calculate AHT based on the amount of historical data available:
If less than 2 years of historical data is available:
-
The algorithm uses a Moving Weighted Average to estimate AHT.
-
This calculation is performed at the interval level, applying weights to recent data points within each time interval (For example, 15-minute or 30-minute blocks).
If more than 2 years of historical data is available:
-
The algorithm evaluates multiple candidate models and selects the one with the lowest Mean Absolute Error (MAE).
-
This model selection is also applied at the interval level, allowing each interval to use the best-fitting model based on its historical AHT behavior.
Summary:
-
< 2 years data: Moving Weighted Average → applied at interval level.
-
≥ 2 years data: Best-fit model selected using MAE → applied at the interval level.